핵심 요약
Ollama에 Qwen 2.5 7B 모델을 설치하면 M2 MacBook Pro에서 초당 35토큰 이상 생성되며, 간단한 코드 작성·한국어 요약 작업에는 ChatGPT와 체감 차이가 거의 없다. 단, 최신 정보 검색이나 복잡한 다단계 추론에서는 여전히 클라우드 LLM이 우위다. 비용 0원·완전 오프라인이라는 장점 덕분에 반복 작업에서 쓸 만하다는 건 확인됐다.
왜 로컬 LLM인가?
클라우드 LLM(ChatGPT, Claude, Gemini)의 대안으로 로컬 LLM을 쓰는 이유는 크게 세 가지다.
- 비용: API 호출 비용 없음. GPT-4o 기준 1M 토큰에 $5~$15인데, 로컬은 전기세만.
- 프라이버시: 입력 내용이 외부 서버로 나가지 않는다. 사내 문서, 코드, 개인 데이터 처리에 딱 맞다.
- 오프라인: 인터넷 없이도 작동. 보안망 환경, 비행기 안에서도 사용 가능.
Ollama 설치 — 10분이면 끝난다
Ollama는 로컬 LLM을 Docker처럼 관리해주는 런타임이다. 모델 다운로드·실행·API 서빙을 CLI 한 줄로 처리한다.
macOS
brew install ollama
또는 공식 사이트에서 .dmg 설치
Linux
curl -fsSL https://ollama.com/install.sh | sh
Windows
공식 사이트에서 .exe 다운로드 후 설치
설치 후 서비스 시작:
ollama serve
기본적으로 http://localhost:11434에서 REST API를 제공한다.
Qwen 모델 선택 — 어떤 사이즈가 맞나?
Qwen 2.5는 알리바바가 개발한 오픈소스 LLM으로, 한국어 이해도가 Meta LLaMA 계열보다 실제로 써보면 더 낫다. Ollama 라이브러리에서 qwen2.5 태그로 바로 설치 가능하다.
ollama pull qwen2.5:7b # 추천 (균형)
ollama pull qwen2.5:1.5b # 초경량, 테스트용
ollama pull qwen2.5:14b # 고품질, RAM 16GB 이상 필요
ollama pull qwen2.5:32b # 최고 품질, RAM 32GB 이상 필요
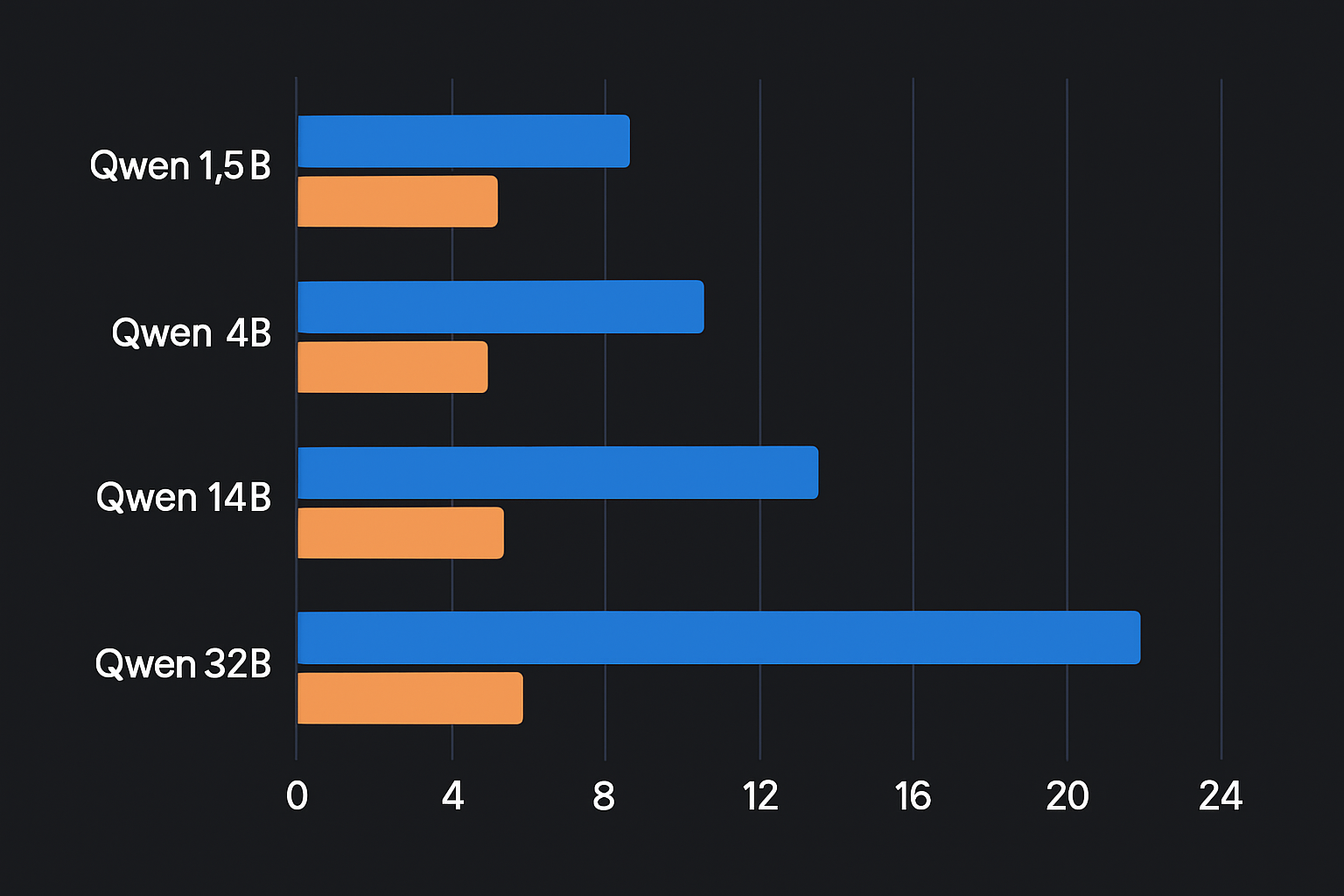
모델 사이즈별 실측 스펙
| 모델 | 다운로드 크기 | 최소 RAM | M2 Pro 속도 | RTX 4090 속도 |
|---|---|---|---|---|
| Qwen2.5:1.5b | 0.9 GB | 4 GB | ~80 tok/s | ~300 tok/s |
| Qwen2.5:7b | 4.7 GB | 8 GB | ~35 tok/s | ~120 tok/s |
| Qwen2.5:14b | 9.0 GB | 16 GB | ~18 tok/s | ~60 tok/s |
| Qwen2.5:32b | 20 GB | 32 GB | ~8 tok/s | ~28 tok/s |
M2 MacBook Pro 16GB + Qwen2.5:7b 기준으로 대부분의 작업에서 체감 답변 속도는 빠르면 3초, 길어도 20초 내외였다.
CLI로 바로 사용하기
설치 후 터미널에서 바로 대화 가능:
ollama run qwen2.5:7b
OpenAI 호환 API로도 사용:
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2.5:7b",
"messages": [{"role": "user", "content": "안녕하세요"}]
}'
기존 OpenAI SDK 코드의 base_url만 http://localhost:11434/v1으로 바꾸면 바로 연동된다.
실제로 써봤더니 — 잘 되는 것 vs 안 되는 것
✅ 실용성 검증된 작업
1. 코드 작성 · 디버깅
# 실제 프롬프트
"Python으로 CSV 파일을 읽어서 이메일 컬럼의 중복을 제거하고 새 파일로 저장하는 스크립트 작성해줘"
Qwen2.5:7b가 12초 만에 올바른 pandas 코드를 생성했다. GPT-4o-mini와 사실상 차이 없음.
2. 한국어 문서 요약
5,000자 분량의 계약서 요약을 요청했을 때, 7B 모델이 핵심 조항 5개를 불릿으로 정리. 내용 누락 없음.
3. 반복 템플릿 생성
이메일 초안, 회의록 정리, 주간 보고서 포맷 작성 등 반복적인 글쓰기 작업에서 비용 걱정 없이 무제한 사용 가능.
4. 오프라인 코드 리뷰
인터넷 없는 보안 환경에서 로컬 코드베이스를 프롬프트에 붙여넣고 리뷰 요청. 완전 격리된 환경에서도 동작.
❌ 한계가 뚜렷한 작업
1. 최신 정보 검색
- 2024년 이후 뉴스, 최신 API 스펙, 실시간 가격 등은 모름
- 학습 데이터 기준일 이후의 내용은 환각(hallucination)이 발생한다
2. 복잡한 다단계 추론
- GPT-4o나 Claude Sonnet 대비 7B 모델의 수학적 추론·논리 퍼즐 정확도는 훨씬 낮다
- 벤치마크(MMLU 기준): Qwen2.5-7B 약 74%, GPT-4o 약 88%
3. 긴 컨텍스트 처리
- Qwen2.5:7b의 컨텍스트 창은 128K이지만, 실제로 32K 이상에서 답변 품질이 눈에 띄게 떨어진다
결론 — 누구에게 추천하나?
| 사용자 유형 | 추천 여부 | 이유 |
|---|---|---|
| API 비용이 부담스러운 개발자 | ✅ 강력 추천 | 반복 작업 비용 0원 |
| 사내 문서를 LLM에 넣고 싶은 직장인 | ✅ 추천 | 데이터 외부 유출 없음 |
| 최신 정보가 필요한 리서처 | ❌ 비추천 | 클라우드 LLM + 검색 연동이 맞다 |
| 모바일·저사양 기기 사용자 | ❌ 비추천 | RAM 8GB 이상 필수 |
| 최고 품질 추론이 필요한 경우 | ⚠️ 조건부 | 32B 모델 이상, 고사양 PC 필요 |
FAQ
Q. RAM이 8GB밖에 없는데 로컬 LLM을 실행할 수 있나요?
네, 가능합니다. Qwen2.5:1.5b(약 2GB RAM 사용)나 Qwen2.5:3b를 사용하면 8GB 환경에서도 실행됩니다. 단, 7B 이상 모델을 8GB 시스템에서 실행하면 스왑 메모리를 사용해 응답 속도가 분당 수 토큰 수준으로 느려집니다.
Q. Ollama 말고 다른 로컬 LLM 런타임도 있나요?
LM Studio가 GUI 기반으로 초보자에게 친화적입니다. 개발자라면 llama.cpp로 직접 실행하는 방식도 있습니다. Ollama는 CLI 중심이라 자동화·스크립트 연동에 가장 편리합니다.
Q. 한국어 성능이 영어 대비 얼마나 떨어지나요?
Qwen 계열은 중국어·영어 중심으로 학습됐지만 한국어 데이터도 포함돼 있어, LLaMA 계열보다 한국어 품질이 낫습니다. 7B 기준 일상적인 한국어 문서 요약·작성은 충분히 실용적이며, 문법 오류 빈도도 낮습니다. 다만 한국어 전용 특화 모델(EXAONE)이 한국어에서 더 자연스러운 경우가 있습니다.
Q. GPU가 없는 CPU 전용 환경에서도 쓸만한가요?
Apple Silicon(M1/M2/M3)은 통합 메모리 구조 덕분에 CPU·GPU를 모두 활용해 꽤 빠른 속도를 냅니다. Intel/AMD CPU 전용 환경(GPU 없음)에서는 7B 모델 기준 초당 3~8토큰으로 매우 느리며, 짧은 응답도 30초 이상 걸릴 수 있습니다.